
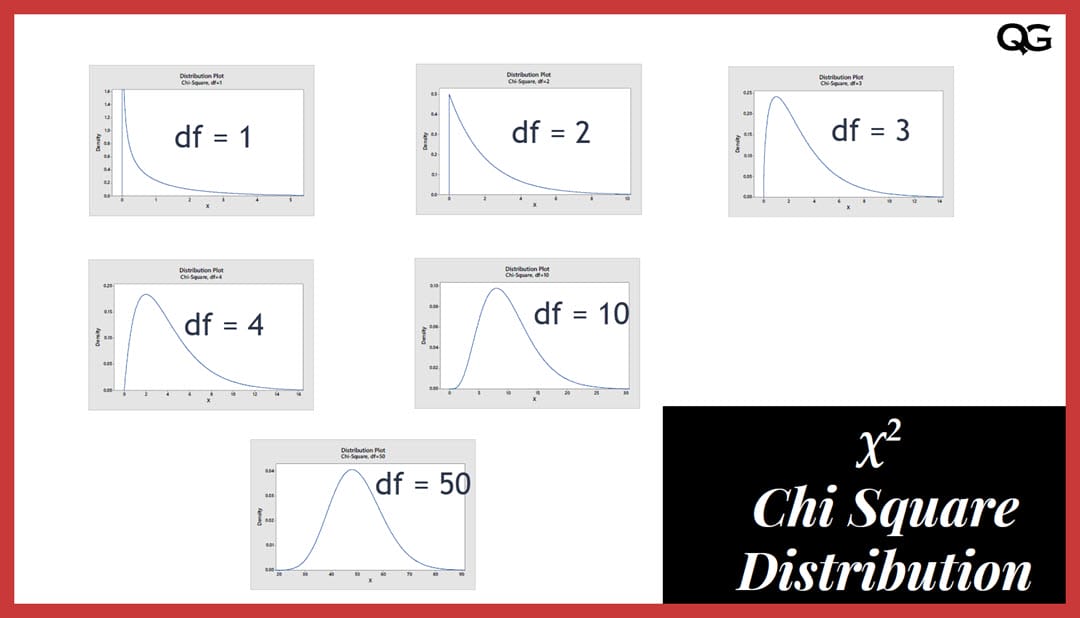
The chi-square distribution is a continuous probability distribution that describes the distribution of the sum of squares of independent standard normal random variables. It is commonly used in statistical hypothesis testing to evaluate the goodness of fit of a model to a set of data. The chi-square distribution is defined by a single parameter, k, which is the number of degrees of freedom.
Properties of Chi-Square Distribution:
The chi-square distribution is a continuous probability distribution that is defined by a single parameter called the degrees of freedom. It has several important properties, including:
- Right-skewed shape: The chi-square distribution is right-skewed, meaning that it has a long tail on the right side of the distribution.
- Non-negative: The chi-square distribution is always non-negative, since the squared values of random variables can never be negative.
- Asymptotic behaviour: The chi-square distribution approaches the x-axis as the values of x become increasingly large. This means that the probability of a value being extremely large is always non-zero but becomes increasingly small as the value becomes more extreme.
- Non-symmetrical: The chi-square distribution is not symmetrically distributed.
- Use in statistical hypothesis testing: The chi-square distribution is often used in statistical hypothesis testing to determine the goodness of fit of a model to a set of data or to test the independence of two variables.
Chi-square Statistic
To use the chi-square distribution in statistical hypothesis testing, you need to calculate the chi-square statistic, which measures how well a model fits a data set. The chi-square statistic is calculated by summing the squared differences between the observed values and the expected values, divided by the expected values.
$$\chi^2 = \sum_{i=1}^n \frac{(O_i - E_i)^2}{E_i}$$
where:
n is the number of data points, O is the observed value for each data point, E is the expected value for each data point
Probability Density Function (PDF):
The probability density function (PDF) of the chi-square distribution is a function that describes the probability of a given value occurring under the distribution. The PDF of the chi-square distribution is defined as:
$$f(x) = \frac{1}{2^{k/2}\Gamma(k/2)} x^{k/2-1} e^{-x/2}$$
where:
\(k\) is the degrees of freedom
\(\Gamma(k/2)\) is the gamma function
Chi-Square Calculator:
Find the area under the Chi-Square Distribution (Left or Right Tail)
Mean, Mode and Variance of Chi-square Distribution
Mean: The mean of the chi-square distribution is equal to the degrees of freedom (df).
$$\mu = df$$
Mode: The mode of the chi-square distribution is equal to the degrees of freedom minus 2 (if the degrees of freedom are greater than 2).
$$mode = (df - 2) \text { for df} \geq 2 $$
Variance: The variance of the chi-square distribution is equal to twice the degrees of freedom.
$$\sigma^2 = 2 \cdot df$$
Standard deviation: The standard deviation of the chi-square distribution is equal to the square root of twice the degrees of freedom.
$$\sigma = \sqrt{2 \cdot df}$$
These are the mean, mode, standard deviation, and variance of the chi-square distribution. They are all related to the degrees of freedom and can be used to describe the shape and spread of the distribution.
Using Microsoft Excel
CHISQ.DIST:
The CHISQ.DIST function in Microsoft Excel calculates the probability density function (PDF) or cumulative distribution function (CDF) of the chi-square distribution. The function has the following syntax:
CHISQ.DIST(x, degrees_freedom, cumulative)
Where:
- x: is the value for which you want to calculate the probability density or cumulative probability.
- degrees_freedom: is the number of degrees of freedom in the chi-square distribution.
- cumulative: is a logical value that specifies whether you want to calculate the PDF (FALSE) or CDF (TRUE) of the chi-square distribution.
The function returns the probability density or cumulative probability of the given value under the chi-square distribution with the specified degrees of freedom.
CHISQ.INV:
The CHISQ.INV function in Microsoft Excel calculates the inverse of the chi-square distribution for a given probability and degrees of freedom. The function has the following syntax:
CHIINV(probability, degrees_freedom)
where:
- probability: is the probability for which you want to find the corresponding value under the chi-square distribution. This should be a value between 0 and 1.
- degrees_freedom: is the number of degrees of freedom in the chi-square distribution.
The function returns the value of the chi-square statistic corresponding to the given probability and degrees of freedom.
CHISQ.DIST.RT:
The CHISQ.DIST.RT function in Microsoft Excel calculates the right-tailed probability of the chi-square distribution for a given value and degrees of freedom. The function has the following syntax:
CHISQ.DIST.RT(x, degrees_freedom)
where:
- x: is the value for which you want to calculate the right-tailed probability.
- degrees_freedom: is the number of degrees of freedom in the chi-square distribution.
The function returns the right-tailed probability of the given value under the chi-square distribution with the specified degrees of freedom.
CHISQ.INV.RT:
The CHISQ.INV.RT function in Microsoft Excel calculates the inverse of the right-tailed probability of the chi-square distribution for a given probability and degrees of freedom. The function has the following syntax:
CHIINV.RT(probability, degrees_freedom)
where:
- probability: is the right-tailed probability for which you want to find the corresponding value under the chi-square distribution. This should be a value between 0 and 1.
- degrees_freedom: is the number of degrees of freedom in the chi-square distribution.
The function returns the value of the chi-square statistic corresponding to the given right-tailed probability and degrees of freedom.
Conclusion
In conclusion, the chi-square distribution is a probability distribution used in statistical analysis to test the goodness of fit of a model to a set of data and to test the independence of two variables. It is defined by the degrees of freedom.