
Statistical Process Control (SPC) is a cornerstone quality management and engineering methodology. It helps businesses understand, manage, and optimize their processes. One of the critical elements in statistical process control is the concept of subgrouping. Specifically, what are rational subgroups, how do they work, and why are they essential for effective process control? This article looks into the ins and outs of rational subgrouping, addressing critical questions related to subgroups' size, scope, and relevance in a control chart environment.
The Importance of Variation
Before diving into subgroups, it's crucial to understand the different types of variations that processes can exhibit:
Special Cause Variation: Fluctuations in data points that occur due to specific, identifiable factors, often outliers.
Common Cause Variation: The natural or inherent variations in a process over time, often expected and based on random causes that are not easily identifiable.
Understanding these types of variations helps in the correct setup and interpretation of control charts.
What is a Subgroup?
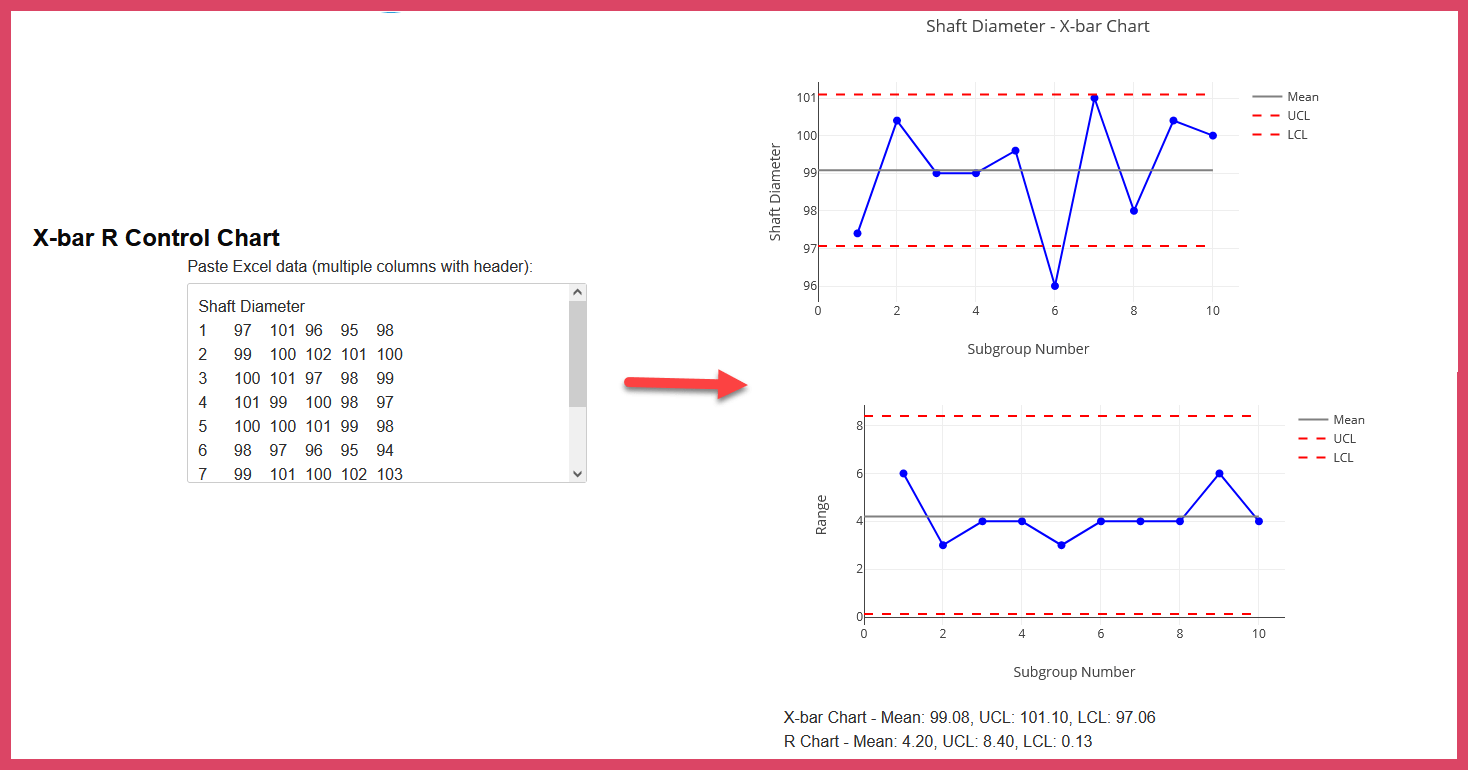
A subgroup is essentially a snapshot of the process at a given time. In a manufacturing line producing rods, for example, if you pick five rods and measure them, these measurements represent a subgroup. This subgroup, in turn, represents the state of the production process at that specific time.
The Role of Rational Subgroups
Rational subgroups have a particular significance; they are designed to capture only the common cause variation within the process, thereby serving as a clear lens through which the process stability can be assessed.
In practical terms, this means that all items in a rational subgroup should be produced under conditions that are as constant as possible. They should be produced consecutively and under the same set of conditions. For instance, do not pick items from a bin containing products made at different times or under different conditions.
Deciding the Size of a Subgroup
So, how do you determine what the size of the subgroup should be? The size should be small enough to detect meaningful shifts in the process but large enough not to trigger false alarms for trivial fluctuations. Generally speaking, a subgroup size of 5 is often used as it offers a good balance.
The Math Behind Subgroup Size
The Central Limit Theorem (CLT) plays a pivotal role here. According to CLT, as the subgroup size (n) increases, the distribution of the sample means will approximate a normal distribution, regardless of the shape of the population distribution. Therefore, as your subgroup size increases, your control chart limits will narrow, making the chart more sensitive to special cause variation and more prone to false alarms.
Types of Variation Within and Between Subgroups
Variation Within Subgroup: This is the range of measurements within a single subgroup.
Variation Between Subgroups: This is the variation observed between the means of different subgroups over time.
Understanding these two types of variation is crucial for setting up and interpreting control charts like x-bar and r-charts. The x-bar chart showcases variation between subgroups, whereas the r-chart captures the range and, thus, the variation within subgroups.
Implications for Control Charts
If you observe too much variation within subgroups, it will lead to broader control limits on the chart. This could mask special cause variation and reduce the control chart's sensitivity to changes in the process. Therefore, a judicious choice of subgroup size and understanding of both within and between subgroup variations is crucial for effectively using control charts.
Conclusion
Rational subgrouping is not just a statistical requirement but a practical necessity for any organization aiming to implement Statistical Process Control effectively. It serves as a bridge between the theoretical aspects of quality control and their real-world applications. Understanding the concept of rational subgrouping and its nuances could be the key to unlocking more valuable insights from your process data and, ultimately, achieving higher quality and efficiency levels.